 浏览器的事件循环
浏览器的事件循环
# 浏览器的事件循环
# 什么是事件,什么事件模型重要
事件概念
是用户操作网页的时候发生的交互动作,比如click/move,除了这些还可以是文档加载,窗口滚动和大小调整,事件被封装成一个event对象,包含了该事件发生的所有相关信息以及可以对事件进行的操作
事件模型
DOM0级事件模型,这种模型不会传播,所以没有时间流的概念,他在网页中直接定义监听函数,在dom对象上注册事件名称IE事件模型 一次事件共有两个过程,事件处理阶段和事件冒泡阶段,事件处理阶段会首先执行目标元素绑定的监听事件,然后是事件冒泡阶段,就是事件从目标元素冒泡到document,依次检查经过的节点是否绑定了事件监听函数,有的话就执行,这种通过attachEvent添加监听函数,可以添加多个监听函数,会按顺序执行DOM2级事件模型 一个是事件捕获,是从是事件从document一直向下传播到目标元素,依次检查经过的节点是否绑定了事件监听函数,如果有则执行。后面两个阶段和IE事件模型的两个阶段相同。这种事件模型,事件绑定的函数是addEventListener,其中第三个参数可以指定事件是否在捕获阶段执行。
# 如何阻止事件冒泡特别重要
- 普通浏览器使用:
event.stopPropagation() IE浏览器使用:event.cancelBubble = true
# 如何阻止事件捕获特别重要
- 普通浏览器使用:
event.preventDefault() IE浏览器使用:window.event.returnValue = false
# 在一个DOM上同时绑定两个点击事件:一个用捕获,一个用冒泡。事件会执行几次,先执行冒泡还是捕获?特别重要
- 该
DOM上的事件如果被触发,会执行两次(执行次数等于绑定次数) - 如果该
DOM是目标元素,则按事件绑定顺序执行,不区分冒泡/捕获 - 如果该
DOM是处于事件流中的非目标元素,则先执行捕获,后执行冒泡
# addEventListener()和attachEvent()的区别
addEventListener()是符合W3C规范的标准方法;attachEvent()是IE低版本的非标准方法addEventListener()支持事件冒泡和事件捕获; - 而attachEvent()只支持事件冒泡addEventListener()的第一个参数中,事件类型不需要添加on;attachEvent()需要添加'on'- 如果为同一个元素绑定多个事件,
addEventListener()会按照事件绑定的顺序依次执行,attachEvent()会按照事件绑定的顺序倒序执行
# 对事件委托的理解特别重要
概念
本质上是利用了浏览器事件冒泡的机制。因为事件在冒泡过程中会上传到父节点,父节点可以通过事件对象获取到目标节点,因此可以把子节点的监听函数定义在父节点上,由父节点的监听函数统一处理多个子元素的事件,这种方式称为事件委托(事件代理)
使用事件委托可以不必要为每一个子元素都绑定一个监听事件,这样减少了内存上的消耗。并且使用事件代理还可以实现事件的动态绑定,比如说新增了一个子节点,并不需要单独地为它添加一个监听事件,它绑定的事件会交给父元素中的监听函数来处理
特点:
减少内存消耗
- 如果把列表的每一个元素都绑定函数就会消耗很大的内存,效率比较低,绑定到父级上的话点击的时候再去匹配目标元素就可以大量减少内存消耗
动态绑定事件
- 如果事件绑定在父级上的话,那么增加和删减子元素就不用重新监听或解绑事件
局限性
focus、blur没有事件冒泡机制,无法实现事件委托,mousemove、mouseout这样的事件,虽然有事件冒泡,但是只能不断通过位置去计算定位,对性能消耗高,因此也是不适合于事件委托的
当然事件委托不是只有优点,它也是有缺点的,事件委托会影响页面性能,主要影响因素有:
- 元素中,绑定事件委托的次数;
- 点击的最底层元素,到绑定事件元素之间的
DOM层数;
在必须使用事件委托的地方,可以进行如下的处理:
- 只在必须的地方,使用事件委托,比如:
ajax的局部刷新区域 - 尽量的减少绑定的层级,不在
body元素上,进行绑定 - 减少绑定的次数,如果可以,那么把多个事件的绑定,合并到一次事件委托中去,由这个事件委托的回调,来进行分发。
# W3C事件的 target 与 currentTarget 的区别
target只会出现在事件流的目标阶段currentTarget可能出现在事件流的任何阶段- 当事件流处在目标阶段时,二者的指向相同
- 当事件流处于捕获或冒泡阶段时:
currentTarget指向当前事件活动的对象(一般为父级)
demo理解一下
<div id="app">
<div class="outer" @click="outer">最外层
<div class="middle" @click="middle">中间
<div class="inner" @click="inner">最内层点击我(^_^)</div>
</div>
</div>
<p></p>
</div>
<script type="text/javascript">
let app = new Vue({
el: '#app',
methods: {
inner: function (e) {
console.log( '触发了inner 事件'+" currentTarget:"+e.currentTarget.className, e.target.className)
},
middle: function (e) {
console.log( '触发了middle事件'+" currentTarget:"+e.currentTarget.className, e.target.className)
},
outer: function (e) {
console.log( '触发了outer事件'+" currentTarget:"+e.currentTarget.className, e.target.className)
}
}
})
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
//当我们点击最内层的元素时候我们会发现 会依次打印
// 触发了inner 事件 currentTarget: inner, inner
// 触发了middle 事件 currentTarget: middle, inner
// 触发了outer 事件 currentTarget: outer, inner
2
3
4
# 同步和异步的区别
- 同步指的是当一个进程在执行某个请求时,如果这个请求需要等待一段时间才能返回,那么这个进程会一直等待下去,直到消息返回为止再继续向下执行。
- 异步指的是当一个进程在执行某个请求时,如果这个请求需要等待一段时间才能返回,这个时候进程会继续往下执行,不会阻塞等待消息的返回,当消息返回时系统再通知进程进行处理。
# 对事件循环的理解特别重要
因为 js 是单线程运行的,在代码执行时,通过将不同函数的执行上下文压入执行栈中来保证代码的有序执行。
在执行同步代码时,如果遇到异步事件,js 引擎并不会一直等待其返回结果,而是会将这个事件挂起,继续执行执行栈中的其他任务。
当同步事件执行完毕后,再将异步事件对应的回调加入到一个任务队列中等待执行。任务队列可以分为宏任务队列和微任务队列,当当前执行栈中的事件执行完毕后,js 引擎首先会判断微任务队列中是否有任务可以执行,如果有就将微任务队首的事件压入栈中执行。
当微任务队列中的任务都执行完成后再去执行宏任务队列中的任务。
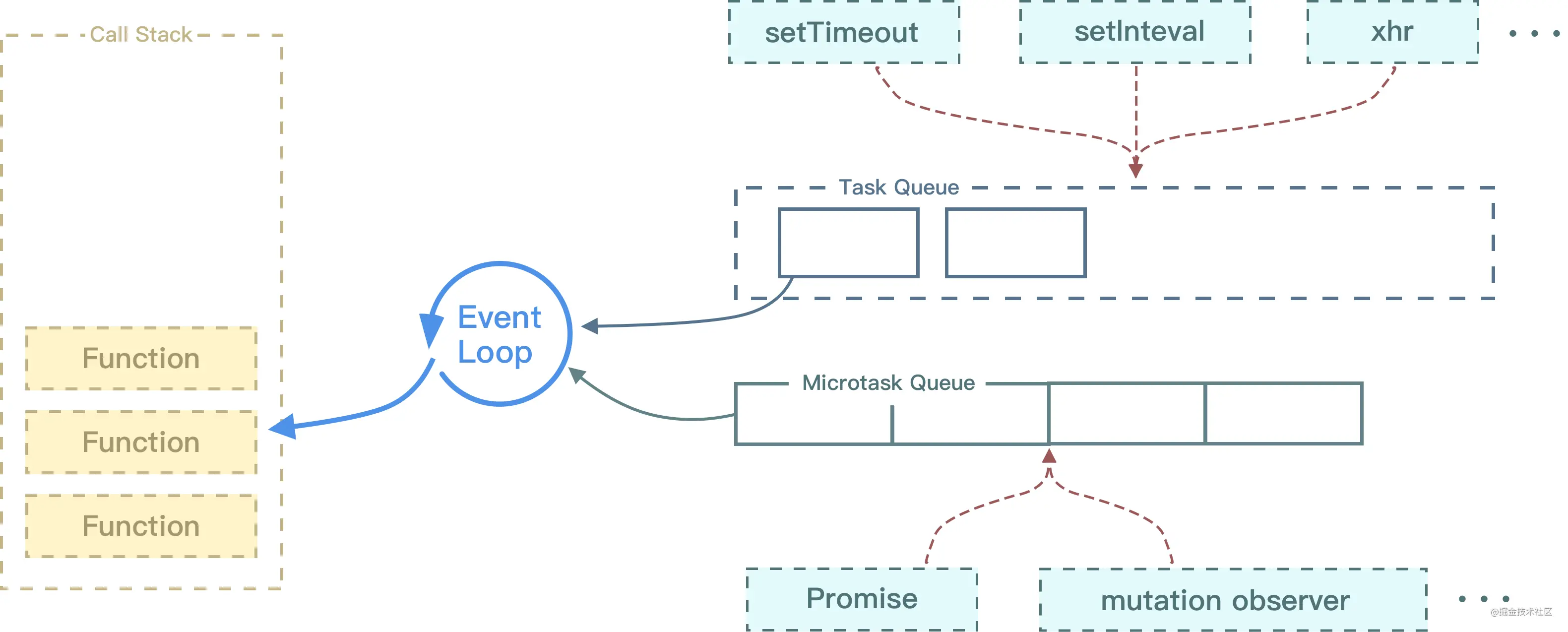
Event Loop 执行顺序如下所示:
首先执行同步代码,这属于宏任务
当执行完所有同步代码后,执行栈为空,查询是否有异步代码需要执行
执行所有微任务
当执行完所有微任务后,如有必要会渲染页面
然后开始下一轮
Event Loop,执行宏任务中的异步代码
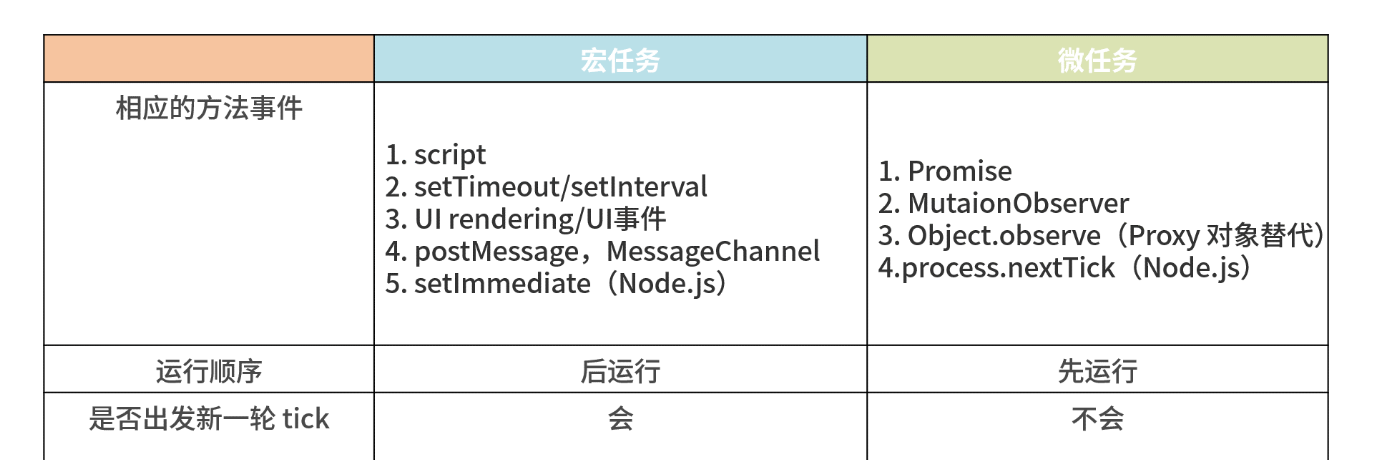
# 宏任务和微任务分别有哪些
- 微任务包括:
promise的回调、node中的process.nextTick、对Dom变化监听的MutationObserver。 - 宏任务包括:
script脚本的执行、setTimeout,setInterval,setImmediate一类的定时事件,还有如I/O操作、UI渲染等
# 介绍一下什么是执行栈

当开始执行 JS 代码时,根据先进后出的原则,后执行的函数会先弹出栈,可以看到,foo 函数后执行,当执行完毕后就从栈中弹出了
# node中的EventLoop和浏览器的区别?process.nextTick执行顺序是什么
Node 的 Event Loop 分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段
┌───────────────────────┐
┌─>│ timers │<————— 执行 setTimeout()、setInterval() 的回调
│ └──────────┬────────────┘
| |<-- 执行所有 Next Tick Queue 以及 MicroTask Queue 的回调
│ ┌──────────┴────────────┐
│ │ pending callbacks │<————— 执行由上一个 Tick 延迟下来的 I/O 回调(待完善,可忽略)
│ └──────────┬────────────┘
| |<-- 执行所有 Next Tick Queue 以及 MicroTask Queue 的回调
│ ┌──────────┴────────────┐
│ │ idle, prepare │<————— 内部调用(可忽略)
│ └──────────┬────────────┘
| |<-- 执行所有 Next Tick Queue 以及 MicroTask Queue 的回调
| | ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │ - (执行几乎所有的回调,除了 close callbacks、timers、setImmediate)
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ | | |
| | └───────────────┘
| |<-- 执行所有 Next Tick Queue 以及 MicroTask Queue 的回调
| ┌──────────┴────────────┐
│ │ check │<————— setImmediate() 的回调将会在这个阶段执行
│ └──────────┬────────────┘
| |<-- 执行所有 Next Tick Queue 以及 MicroTask Queue 的回调
│ ┌──────────┴────────────┐
└──┤ close callbacks │<————— socket.on('close', ...)
└───────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Timers(计时器阶段):初次进入事件循环,会从计时器阶段开始。此阶段会判断是否存在过期的计时器回调(包含setTimeout和setInterval),如果存在则会执行所有过期的计时器回调,执行完毕后,如果回调中触发了相应的微任务,会接着执行所有微任务,执行完微任务后再进入Pending callbacks阶段。Pending callbacks:执行推迟到下一个循环迭代的I/O回调(系统调用相关的回调比如TCP连接失败的回调)。Idle/Prepare:仅供内部使用。Poll(轮询阶段):
- 当回调队列不为空时:会执行回调,若回调中触发了相应的微任务,这里的微任务执行时机和其他地方有所不同,不会等到所有回调执行完毕后才执行,而是针对每一个回调执行完毕后,就执行相应微任务。执行完所有的回调后,变为下面的情况。
- 当回调队列为空时(没有回调或所有回调执行完毕):但如果存在有计时器(
setTimeout、setInterval和setImmediate)没有执行,会结束轮询阶段,进入Check阶段。否则会阻塞并等待任何正在执行的I/O操作完成,并马上执行相应的回调,直到所有回调执行完毕。
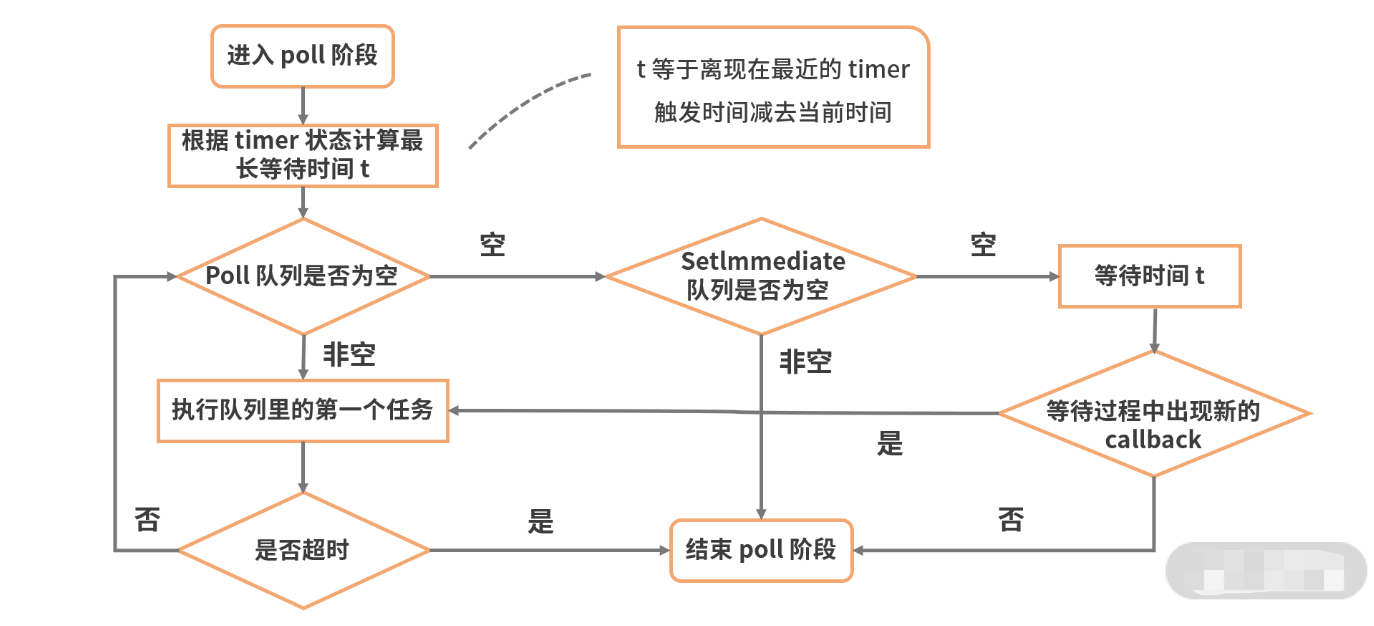
Check(查询阶段):会检查是否存在setImmediate相关的回调,如果不存在则一直停留在Poll阶段轮询 否则到达check阶段执行所有回调,执行完毕后,如果回调中触发了相应的微任务,会接着执行所有微任务,执行完微任务后再进入Close callbacks阶段。Close callbacks:执行一些关闭回调,比如socket.on('close', ...)等。
// 例题
const fs = require("fs");
setTimeout(() => {
// 新的事件循环的起点
console.log("1");
}, 0);
setImmediate(() => {
console.log("setImmediate 1");
});
/// fs.readFile 将会在 poll 阶段执行
fs.readFile("./test.conf", { encoding: "utf-8" }, (err, data) => {
if (err) throw err;
console.log("read file success");
});
/// 该部分将会在首次事件循环中执行
Promise.resolve().then(() => {
console.log("poll callback");
});
// 首次事件循环执行
console.log("2");
// 2 -> poll callback -> 1 read file success -> setImmedate 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
下面来看一个例子,首先在有些情况下,定时器的执行顺序其实是随机的
setTimeout(() => {
console.log('setTimeout')
}, 0)
setImmediate(() => {
console.log('setImmediate')
})
2
3
4
5
6
对于以上代码来说,setTimeout 可能执行在前,也可能执行在后
首先
setTimeout(fn, 0) === setTimeout(fn, 1),这是由源码决定的进入事件循环也是需要成本的,如果在准备时候花费了大于
1ms的时间,那么在timer阶段就会直接执行setTimeout回调那么如果准备时间花费小于
1ms,那么就是setImmediate回调先执行了
当然在某些情况下,他们的执行顺序一定是固定的,比如以下代码:
const fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0)
setImmediate(() => {
console.log('immediate')
})
})
2
3
4
5
6
7
8
9
在上述代码中,setImmediate 永远先执行。因为两个代码写在 IO 回调中,IO 回调是在 poll 阶段执行,当回调执行完毕后队列为空,发现存在 setImmediate 回调,所以就直接跳转到 check 阶段去执行回调了。
上面都是 macrotask 的执行情况,对于 microtask 来说,它会在以上每个阶段完成前清空 microtask 队列,下图中的 Tick 就代表了 microtask

setTimeout(() => {
console.log('timer21')
}, 0)
Promise.resolve().then(function() {
console.log('promise1')
})
2
3
4
5
6
对于以上代码来说,其实和浏览器中的输出是一样的,microtask 永远执行在 macrotask 前面。
最后来看 Node 中的 process.nextTick,这个函数其实是独立于 Event Loop 之外的,它有一个自己的队列,当每个阶段完成后,如果存在 nextTick 队列,就会清空队列中的所有回调函数,并且优先于其他 microtask 执行。
setTimeout(() => {
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
})
})
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
对于以上代码,永远都是先把 nextTick 全部打印出来。
当微任务和宏任务又产生新的微任务和宏任务时,又应该如何处理呢?如下代码所示:
const fs = require('fs');
setTimeout(() => {
console.log('1');
fs.readFile('./config/test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file sync success');
});
}, 0);
fs.readFile('./config/test.conf', {encoding: 'utf-8'}, (err, data) => {
if (err) throw err;
console.log('read file success');
});
Promise.resolve().then(()=>{
console.log('poll callback');
});
console.log('2');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
在上面代码中,有 2 个宏任务和 1 个微任务,宏任务是 setTimeout 和 fs.readFile,微任务是 Promise.resolve。
整个过程优先执行主线程的第一个事件循环过程,所以先执行同步逻辑,先输出
2。接下来执行微任务,输出
poll callback。再执行宏任务中的
fs.readFile 和 setTimeout,由于fs.readFile优先级高,先执行fs.readFile。但是处理时间长于1ms,因此会先执行setTimeout的回调函数,输出1。这个阶段在执行过程中又会产生新的宏任务fs.readFile,因此又将该fs.readFile插入宏任务队列最后由于只剩下宏任务了
fs.readFile,因此执行该宏任务,并等待处理完成后的回调,输出read file sync success// 结果 2 poll callback 1 read file success read file sync success1
2
3
4
5
6
# 事件触发的过程是怎么样的
事件触发有三个阶段:
window往事件触发处传播,遇到注册的捕获事件会触发传播到事件触发处时触发注册的事件
从事件触发处往
window传播,遇到注册的冒泡事件会触发
事件触发一般来说会按照上面的顺序进行,但是也有特例,如果给一个 body 中的子节点同时注册冒泡和捕获事件,事件触发会按照注册的顺序执行
// 以下会先打印冒泡然后是捕获
node.addEventListener(
'click',
event => {
console.log('冒泡')
},
false
)
node.addEventListener(
'click',
event => {
console.log('捕获 ')
},
true
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
通常使用 addEventListener 注册事件,该函数的第三个参数可以是布尔值,也可以是对象。对于布尔值 useCapture 参数来说,该参数默认值为 false ,useCapture 决定了注册的事件是捕获事件还是冒泡事件。对于对象参数来说,可以使用以下几个属性:
capture:布尔值,和useCapture作用一样once:布尔值,值为true表示该回调只会调用一次,调用后会移除监听passive:布尔值,表示永远不会调用preventDefault
一般来说,如果只希望事件只触发在目标上,这时候可以使用 stopPropagation 来阻止事件的进一步传播。通常认为 stopPropagation 是用来阻止事件冒泡的,其实该函数也可以阻止捕获事件。
stopImmediatePropagation 同样也能实现阻止事件,但是还能阻止该事件目标执行别的注册事件。
node.addEventListener(
'click',
event => {
event.stopImmediatePropagation()
console.log('冒泡')
},
false
)
// 点击 node 只会执行上面的函数,该函数不会执行
node.addEventListener(
'click',
event => {
console.log('捕获 ')
},
true
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16