 情景题
情景题
# 情景题
# 当在浏览器输入google.com回车之后会发生什么本博客最重要的一个问题
在回车之前,会执行一次当前页面的
beforeunload事件,可以让页面退出之前执行一些数据清理工作,或者,有表单没有提交的情况提示用户是否确认离开缓存判断 判断资源是否存在缓存中,若在缓存且没有失效,就直接使用,否则向服务器发起新请求
这里的缓存主要指的是
- 如果是
https的话,有可能先找Service Worker,比如你设置了请求拦截,离线缓存的话 - 如果没有,再找浏览器的内存缓存(
Memory Cache) - 如果还没有,再找硬盘缓存(
Disk Cache)( 强缓存和协商缓存都属于硬盘缓存) - 如果这三种都没有找到,请求还是
http2的话,还可能会查找推送缓存(Push Cache),就是找Session(Session会话结束就会释放,所以存在时间很短)
- 如果是
解析
URL对URL进行解析,分析所用的传输协议 域名 端口 资源路径,如果不合法,就传递给搜索引擎,如果没问题,浏览器检查URL是否出现非法字符,若有则进行转义DNS解析- 首先在浏览器缓存中查找对应的
IP地址,如果查到就直接返回,查不到就下一步 - 将请求发给本地
dns服务器,在本地域名服务器查询,如果查到直接返回,差不到就下一步 - 本地
dns服务器向根域名服务器发送请求,根域名服务器返回一个所查询域的顶级服务器地址 - 本地
dns向顶级域名服务器发送请求,接收请求的服务器查询自己的缓存,如果有记录就返回查询结果,没有就返回下一级的权威域名服务器地址 - 本地
dns向权威域名服务器请求,域名服务器返回对应结果 - 本地
dns将结果保存在缓存中,便于下次使用 - 将结果返回给浏览器
- 首先在浏览器缓存中查找对应的
- (用户向本地
dns服务器发起请求是递归请求,本地dns向各级域名服务器发起的请求是迭代请求)
服务器作用笔记
- 根域名服务器:离用户较近,当所要查询的主机也属于同一个本地
ISP时,该本地域名服务器立即就能将所查询的主机名转换为它的IP地址,而不需要再去询问其他的域名服务器。 - 根域名服务器:最高层次、最重要的服务器,所有的根域名服务器都知道所有的顶级域名服务器的域名和
IP地址。不管是哪一个本地域名服务器,若要对因特网上任何一个域名进行解析,只要自己无法解析,就首先求助于根域名服务器 - 顶级域名服务器: 负责管理在该顶级域名服务器注册的所有二级域名。当收到
DNS查询请求时,就给出相应的回答(可能是最后的结果,也可能是下一步应当找的域名服务器的IP地址)。 - 权限域名服务器是负责一个区的域名服务器,用来保存该区中的所有主机的域名到
IP地址的映射。当一个权限域名服务器还不能给出最后的查询回答时,就会告诉发出查询请求的DNS客户,下一步应当找哪一个权限域名服务器。
值得注意的是
- 如果没有配置
CDN,就直接返回解析到的IP - 如果有配置
CDN,权威域名会返回一个CName别名记录,它指向CDN网络中的智能DNS负载均衡系统,然后负载均衡系统通过智能算法,将最佳CDN节点的IP返回
获取
MAC地址 当浏览器得到ip地址时,数据传输还得知道mac地址,数据是从应用层下发到传输层,tcp会指定源端口号和目的端口号,然后下发给网络层,网络层将本地ip作为源地址,获取的ip作为目的ip,然后下发给数据链路层,数据链路层要加入通信双方的mac地址,本地mac作为源mac地址,目的mac地址分情况处理,通过ip地址与本地子网掩码相与,判断是否和请求主机处于同一个子网,如果在同一子网,用ARP协议获得目的主机的mac地址,如果不在,请求转发给网关,由他来转发,此时同样可以通过arp协议获得网关的mac地址,此时目的主机的mac地址为网关的地址TCP三次握手 下面是TCP建立连接的三次握手的过程。
- 首先客户端向服务器发送一个
SYN连接请求报文段和一个随机序号,进入SYN-SENT状态 - 服务端接收到请求后向客户端发送一个
SYN ACK报文段,确认连接请求,并且也向客户端发送一个随机序号,进入LISTEN状态 - 客户端接收服务器的确认应答后,进入连接建立的状态,同时向服务器也发送一个
ACK确认报文段,进入ESTABLISH状态 - 服务器端接收到确认后,也进入连接建立状态,此时双方的连接就建立起来了,也进入
ESTABLISH状态- 两次握手不行的简单原因:服务器就没有办法知道自己的序号是否 已被确认,防止失效的连接请求报文段突然又传送到主机
B。
- 两次握手不行的简单原因:服务器就没有办法知道自己的序号是否 已被确认,防止失效的连接请求报文段突然又传送到主机
HTTPS握手 通信还存在TLS的四次挥手
首先客户端向服务端发送协议的版本号、一个随机数和可以使用的加密方法
服务器收到后确认加密方法,向客户端发送一个随机数和自己的数字证书
客户端收到后检查数字证书是否有效,有效的话再生成一个随机数,使用证书的公钥对随机数加密 然后发给服务端,并且会提供一个前面所有内容的
hash值给服务器检验服务器接收后用私钥对数据解密,同时向客户端发送一个前面所有内容的
hash值供客户端检验,双方这时有三个随机数,按之前的加密方法,使用这三个随机数生成一把密钥,以后双方传输数据时用这个密钥加密再传输
返回数据 当页面请求发到服务端,服务端会返回一个
html文件作为响应,浏览器接到响应 对html进行解析,开始页面渲染TCP四次挥手 最后一步是TCP断开连接的四次挥手过程。
- 若客户端认为数据发送完成,则它需要向服务端发送连接释放请求,进入
FIN_WAIT1状态。 - 服务端收到连接释放请求后,会告诉应用层要释放
TCP链接。然后会发送ACK包,并进入CLOSE_WAIT状态,此时表明客户端到服务端的连接已经释放,不再接收客户端发的数据了。但是因为TCP连接是双向的,所以服务端仍旧可以发送数据给客户端, 此时服务端处于CLOSE_WAIT,客户端收到确认报文后处于FIN_WAIT2状态 - 服务端如果此时还有没发完的数据会继续发送,完毕后会向客户端发送连接释放请求,然后服务端便进入
LAST-ACK状态 - 客户端收到释放请求后,向服务端发送确认应答,此时客户端进入
TIME-WAIT状态。该状态会持续2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有服务端的重发请求的话,就进入CLOSED状态。 - 当服务端收到确认应答后,也便进入
CLOSED状态。- 四次挥手简单原因:服务端还没发完消息
- 等待
2MSL简单原因是:防止发送给服务器的确认报文段丢失或者出错,从而导致服务器 端不能正常关闭。
- 解析响应数据
如果返回的状态码是301或302就需要重定向到其他URL,在重定向地址会在响应头的Location字段中,然后一切从头开始,否则然后根据情况选择关闭TCP连接或者保留重用
然后网络线程会通过SafeBrowsing来检查站点是不是恶意站点,如果是就展示警告页面,告诉你这个站点有安全问题,浏览器会阻止访问,当然也可以强行继续访问。
SafeBrowsing是谷歌内部的一套站点安全系统,通过检查该站点的数据来判断是不是安全,比如通过查看该站点的IP有没有在谷歌黑名单中,如果是Chrome浏览器的话
响应成功返回状态码2xx,然后判断资源能不能缓存,如果可以就先缓存起来
然后对响应解码,比如gzip压缩,然后根据资源类型(Content-Type)决定如何处理,如果浏览器判断是下载文件,那么请求会被提交给浏览器的下载管理器,同时URL请求流程就结束了
否则网络线程会通知UI线程,然后UI线程会创建一个渲染器进程来准备渲染页面
然后浏览器进程通过IPC管道将数据传给渲染器进程的主线程,准备渲染流程
默认情况下会为每一个标签页配置一个渲染进程,但是也有例外,比如从
A页面里面打开一个新的页面B页面,而A页面和B页面又属于同一站点的话,A和B就共用一个渲染进程,其他情况就为B创建一个新的渲染进程
渲染进程收到确认消息后,会和网络进程建立传输数据的管道,开始执行解析数据、下载资源等
为什么进入新页面,之前的页面不会立马消失,而是要加载一会才会更新的原因
- 因为这时候的旧的文档还在网络进程中,渲染进程准备好了之后,渲染进程会向浏览器进程发出提交文档的消息
- 浏览器进程收到后会开始清理当前的旧页面的文档,然后发出确认消息给渲染进程,同时浏览器更新浏览器界面(安全状态、
URL、前进后退历史状态)并更新页面(此时是空白页)
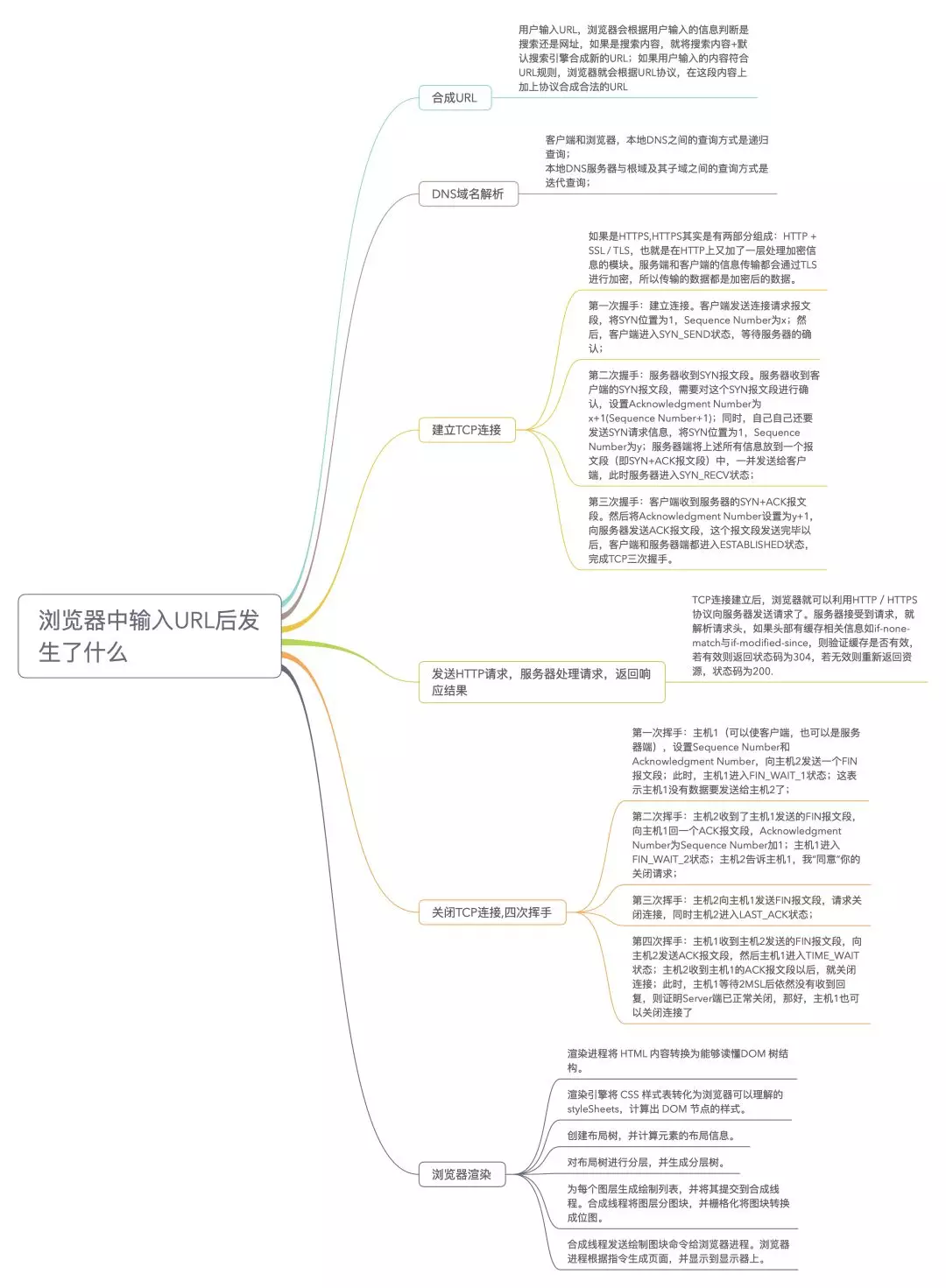
- 页面渲染
渲染进程将
HTML内容转换为能够读懂DOM树结构。渲染引擎将
CSS样式表转化为浏览器可以理解的styleSheets,计算出DOM节点的样式。创建布局树,并计算元素的布局信息。
对布局树进行分层,并生成分层树。
为每个图层生成绘制列表,并将其提交到合成线程。合成线程将图层分图块,并栅格化将图块转换成位图。
合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上
笔记
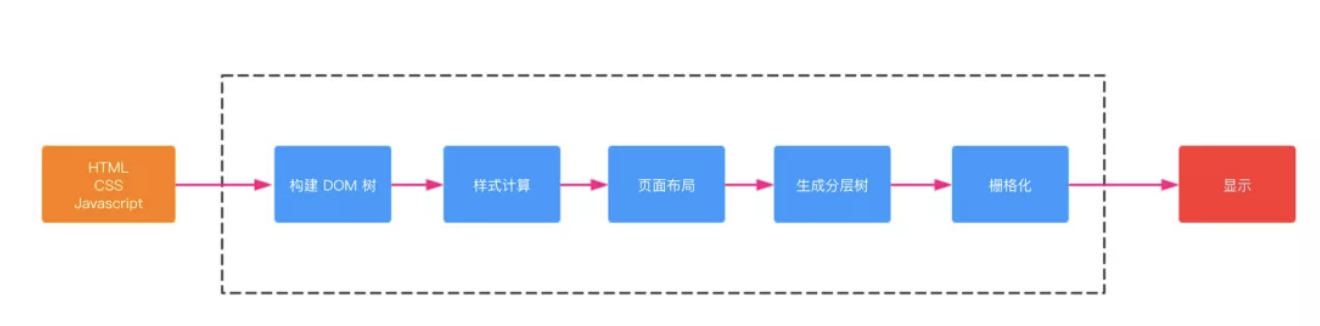
其中的构建
dom树的过程如下- 转码(
Bytes -> Characters)—— 读取接收到的HTML二进制数据,按指定编码格式将字节转换为HTML字符串 Tokens化(Characters -> Tokens)—— 解析HTML,将HTML字符串转换为结构清晰的Tokens,每个Token都有特殊的含义同时有自己的一套规则- 构建
Nodes(Tokens -> Nodes)—— 每个Node都添加特定的属性(或属性访问器)也叫词法分析:将token转换为对象并定义属性和规则,通过指针能够确定Node的父、子、兄弟关系和所属treeScope(例如:iframe的treeScope与外层页面的treeScope不同) - 构建
DOM树(Nodes -> DOM Tree)—— 最重要的工作是建立起每个结点的父子兄弟关系(解析器会维护一个解析栈,栈底为document,也就是DOM树的根节点,然后根据节点对象关系按顺序依次向解析栈添加,形成DOM树)
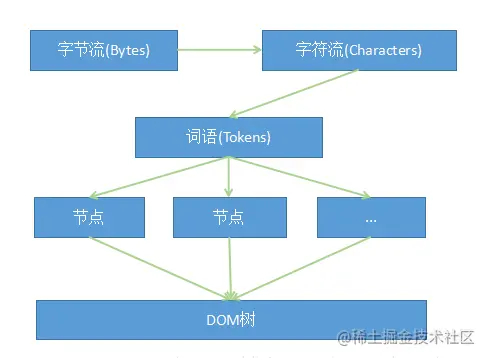
DOM树 和 渲染树 的区别:DOM树与HTML标签一一对应,包括head和隐藏元素- 渲染树不包括
head和隐藏元素,大段文本的每一个行都是独立节点,每一个节点都有对应的css属性
样式计算
渲染引擎将
CSS样式表转化为浏览器可以理解的styleSheets,计算出DOM节点的样式。值得注意的是
CSS解析和DOM解析是可以同时进行的,但是script执行和CSS解析不能同时进行,CSS会阻塞JS执行因为
JS执行时可能在文档的解析过程中 获取样式信息,如果样式信息没有加载和解析完毕,JS就会得到错误的值,所以会延迟JS执行CSS样式来源主要有3种,分别是通过link引用的外部CSS文件、style标签内的CSS、元素的style属性内嵌的CSS。页面布局
布局过程,即
排除 script、meta 等功能化、非视觉节点,排除display: none的节点,计算元素的位置信息,确定元素的位置,构建一棵只包含可见元素布局树。如图
生成分层树
页面中有很多复杂的效果,如一些复杂的
3D变换、页面滚动,或者使用z-index做z轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)具体
拥有层叠上下文属性的元素,比如:
htmlz-index不为autoposition:fixedopacity小于1transform不为nonefilter不为none-webkit-overflow-scrolling:touch有
裁剪的地方,比如内容溢出裁剪不裁剪出现滚动条的话,
滚动条也会被提升为单独的层
栅格化
合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图
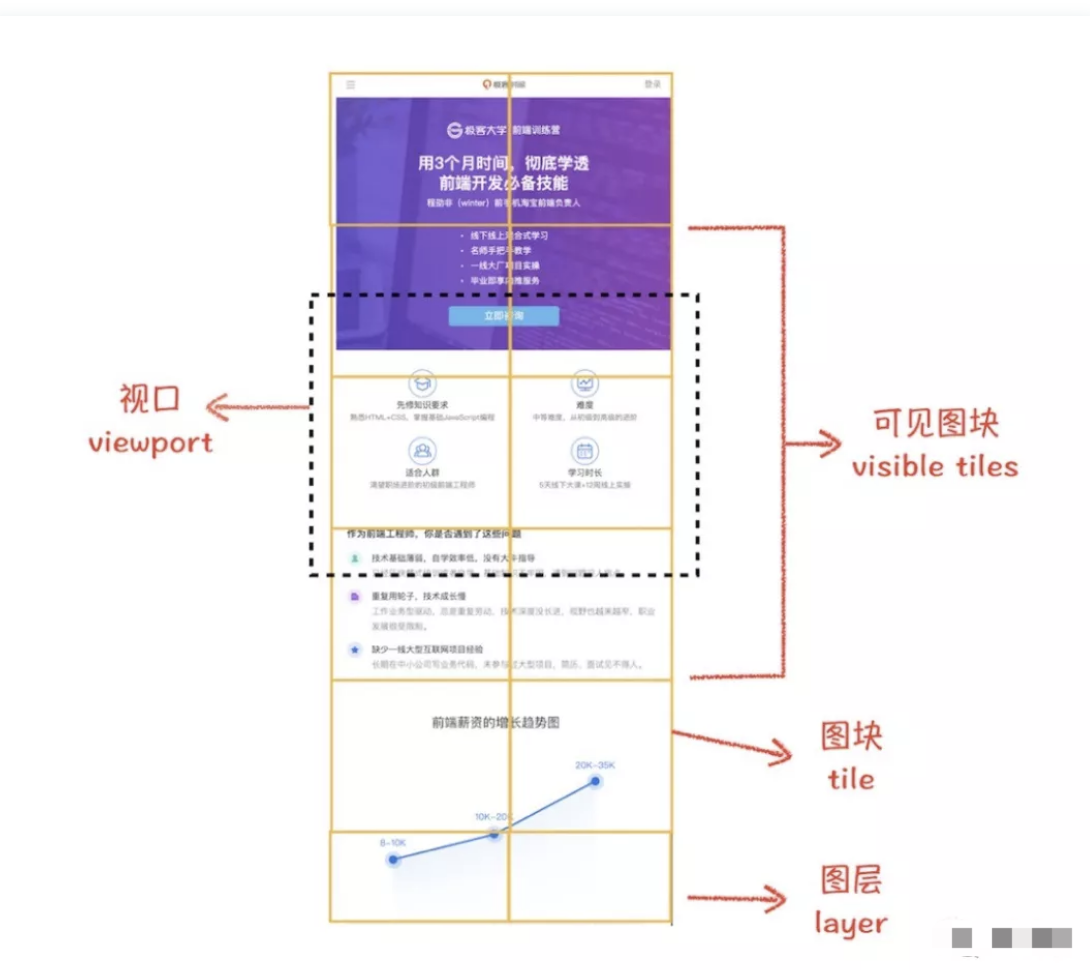
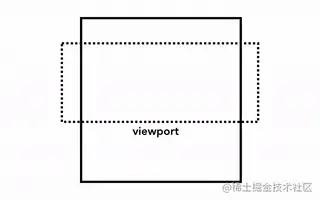
通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(
viewport)。在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。另外渲染引擎还维护了一个栅格化(光栅化)线程,合成线程将分割好的图块发送给
栅格化线程,然后分别栅格化每个图块,再将栅格化之后的图块存储在GPU内存中合成器线程能够对不同的栅格化线程做优先处理,所以出现在视口内的图块会被优先栅格化
- 转码(
- 合成和显示:当图块都被栅格化完成后,合成线程会收集栅格化线程的
draw quads图块信息,该信息记录了图块在内存中的位置信息和图块在页面中的位置信息
根据这些信息,合成器线程生成一个合成器帧,然后通过IPC传给浏览器进程
浏览器进程里有个叫 viz 的组件,用来接收这个合成器帧
然后浏览器进程再将合成器帧绘制到显存中,再通过 GPU 渲染在屏幕上,这时候终于看到了页面内容
当屏幕内容发生变化,比如滚动了页面,合成器线程就会将栅格化好的层合成一个新的合成器帧,新的帧再传到显存,GPU 再渲染到页面上
延伸
这里可以问到transform不用重排,不会导致卡顿的原因
刚才的流程我们知道栅格化的整个流程是不占用主线程的,只在合成器线程和栅格线程中运行
这就意味着它不用JS抢主线程,刚才提到反复重绘和重排会导致掉帧,是因为JS阻塞了主线程,而通过CSS中的动画属性transform实现的动画不会经过布局和绘制,而是直接运行在合成器线程和栅格化线程中,所以不会受到主线程JS执行的影响
更重要的是通过transform实现的动画由于不需要经过布局和绘制,样式计算等操作,所以节省了很多运算时间
补充 两种合成
# 显式合成
下面是显式合成的情况:
一、 拥有层叠上下文的节点。
层叠上下文也基本上是有一些特定的CSS属性创建的,一般有以下情况:
HTML根元素本身就具有层叠上下文。- 普通元素设置
position不为static并且设置了z-index属性,会产生层叠上下文。 - 元素的
opacity值不是1 - 元素的
transform值不是none - 元素的
filter值不是none - 元素的
isolation值是isolate will-change指定的属性值为上面任意一个。
二、需要剪裁的地方。
比如一个div,你只给他设置 100 * 100 像素的大小,而你在里面放了非常多的文字,那么超出的文字部分就需要被剪裁。当然如果出现了滚动条,那么滚动条会被单独提升为一个图层。
# 隐式合成
接下来是隐式合成,简单来说就是层叠等级低的节点被提升为单独的图层之后,那么所有层叠等级比它高的节点都会成为一个单独的图层。
这个隐式合成其实隐藏着巨大的风险,如果在一个大型应用中,当一个z-index比较低的元素被提升为单独图层之后,层叠在它上面的的元素统统都会被提升为单独的图层,可能会增加上千个图层,大大增加内存的压力,甚至直接让页面崩溃。这就是层爆炸的原理。
值得注意的是,当需要repaint时,只需要repaint本身,而不会影响到其他的层。
JS引擎解析过程:调用JS引擎执行JS代码(JS的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)
- 创建
window对象:window对象也叫全局执行环境,当页面产生时就被创建,所有的全局变量和函数都属于window的属性和方法,而DOM Tree也会映射在window的doucment对象上。当关闭网页或者关闭浏览器时,全局执行环境会被销毁。 - 加载文件:完成
js引擎分析它的语法与词法是否合法,如果合法进入预编译 - 预编译:在预编译的过程中,浏览器会寻找全局变量声明,把它作为
window的属性加入到window对象中,并给变量赋值为'undefined';寻找全局函数声明,把它作为window的方法加入到window对象中,并将函数体赋值给他(匿名函数是不参与预编译的,因为它是变量)。而变量提升作为不合理的地方在ES6中已经解决了,函数提升还存在。 - 解释执行:执行到变量就赋值,如果变量没有被定义,也就没有被预编译直接赋值,在
ES5非严格模式下这个变量会成为window的一个属性,也就是成为全局变量。string、int这样的值就是直接把值放在变量的存储空间里,object对象就是把指针指向变量的存储空间。函数执行,就将函数的环境推入一个环境的栈中,执行完成后再弹出,控制权交还给之前的环境。JS作用域其实就是这样的执行流机制实现的。
补充:显示器显示图像的原理
无论是 PC 还是手机屏幕,都有一个固定的刷新频率,一般是 60 HZ,即 60 帧,也就是一秒更新 60 张图片,一张图片停留的时间约为 16.7 ms。
而每次更新的图片都来自显卡的前缓冲区。而显卡接收到浏览器进程传来的页面后,会合成相应的图像,并将图像保存到后缓冲区,然后系统自动将前缓冲区和后缓冲区对换位置,如此循环更新。
这也就是当某个动画大量占用内存的时候,浏览器生成图像的时候会变慢,图像传送给显卡就会不及时,而显示器还是以不变的频率刷新,因此会出现卡顿,也就是明显的掉帧现象
# 扫码登陆流程
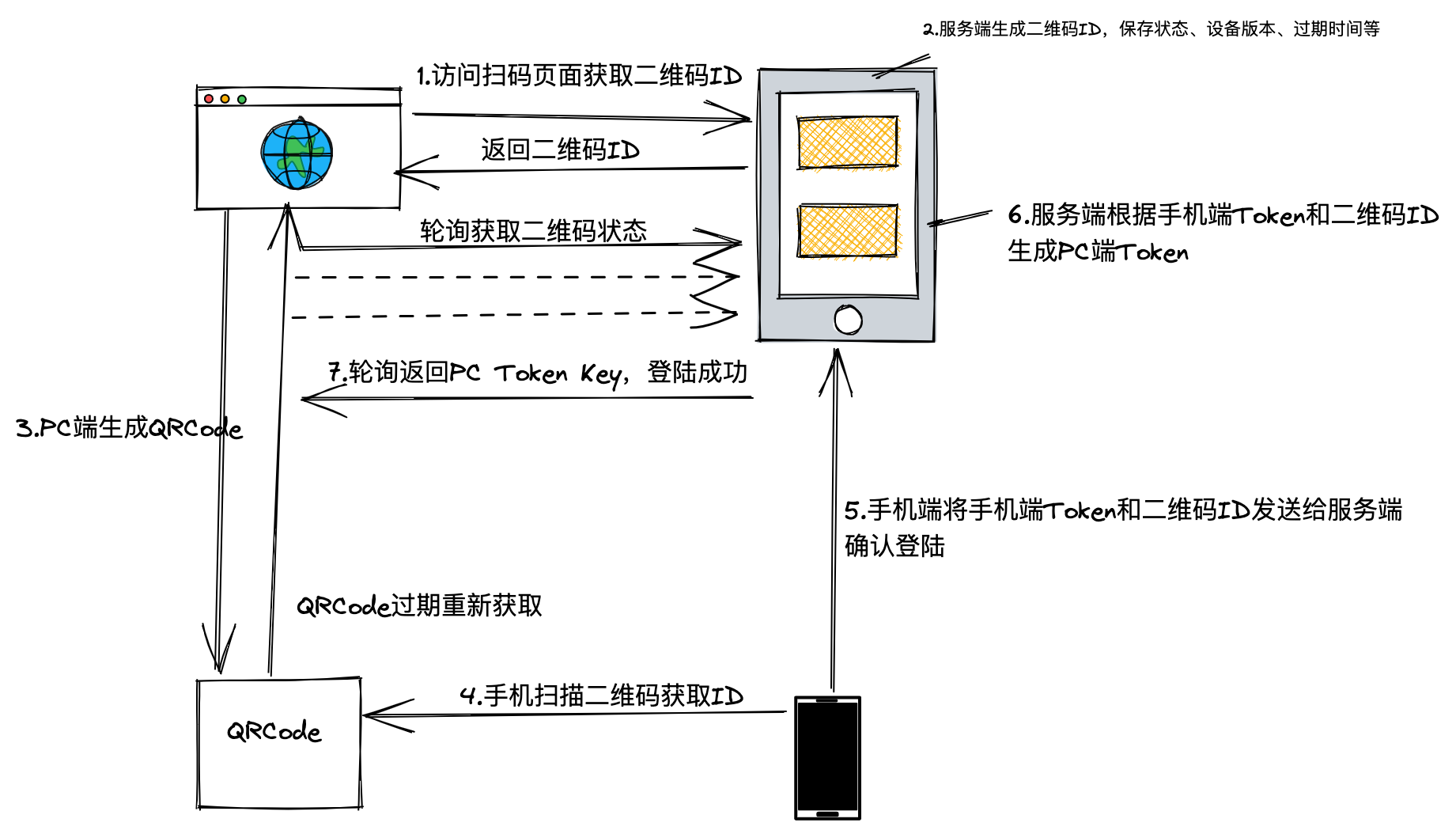
问:假设扫码途中QRCode刷新了怎么办?
可以在PC端新增状态,已扫码待确认,来阻止轮询超时重新获取二维码
问:PC怎么根据二维码进行响应
PC端可以通过获取二维码的状态来进行相应的响应:
- 二维码
未扫描:无操作 - 二维码
已失效:提示刷新二维码 - 二维码
已成功:从服务端获取PC token
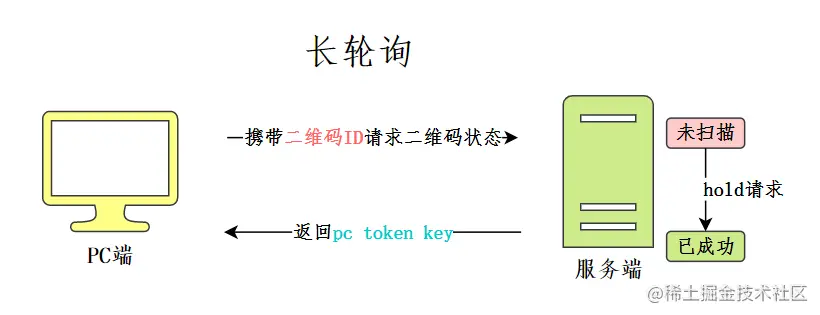
问:可以用长轮询嘛 ws呢
可以。长轮询是指客户端主动给服务端发送二维码状态的查询请求,服务端会按情况对请求进行阻塞,直至二维码信息更新或超时。当客户端接收到返回结果后,若二维码仍未被扫描,则会继续发送查询请求,直至状态变化(已失效或已成功)
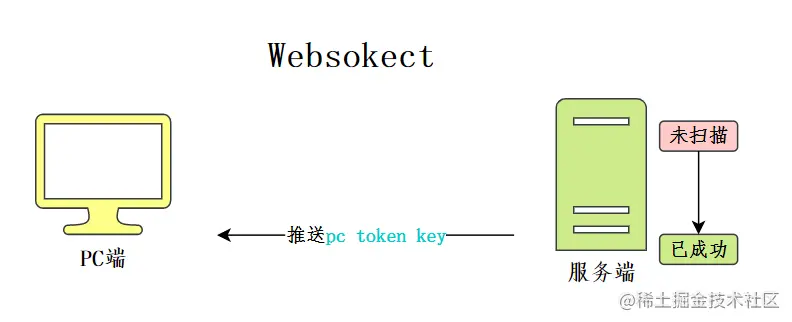
Websocket是指前端在生成二维码后,会与后端建立连接,一旦后端发现二维码状态变化,可直接通过建立的连接主动推送信息给前端。
# 为什么通常在发送数据埋点请求的时候使用的是 1x1 像素的透明 gif 图片重要
- 能够完成整个
HTTP请求+响应(尽管不需要响应内容) - 触发
GET请求之后不需要获取和处理数据、服务器也不需要发送数据 - 跨域友好
- 执行过程无阻塞
- 相比
XMLHttpRequest对象发送GET请求,性能上更好 GIF的最低合法体积最小(最小的BMP文件需要74个字节,PNG需要67个字节,而合法的GIF,只需要43个字节)
为什么不能用请求其他文件资源(js/css/ttf)的方式进行上报呢
创建资源节点后只有将对象注入到浏览器DOM树后,浏览器才会实际发送资源请求。而且载入js/css资源还会阻塞页面渲染,影响用户体验。
构造图片打点不仅不用插入DOM,只要在js中new出Image对象就能发起请求,而且还没有阻塞问题,在没有js的浏览器环境中也能通过img标签正常打点。
同样都是图片,上报时选用了1x1的透明GIF,而不是其他的PNG/JEPG/BMP文件
首先,1x1像素是最小的合法图片。而且,因为是通过图片打点,所以图片最好是透明的,这样一来不会影响页面本身展示效果,二者表示图片透明只要使用一个二进制位标记图片是透明色即可,不用存储色彩空间数据,可以节约体积。因为需要透明色,所以可以直接排除JEPG。
同样的响应,GIF可以比BMP节约41%的流量,比PNG节约35%的流量。GIF才是最佳选择。
- 可以进行跨域
- 不会携带
cookie - 不需要等待服务器返回数据
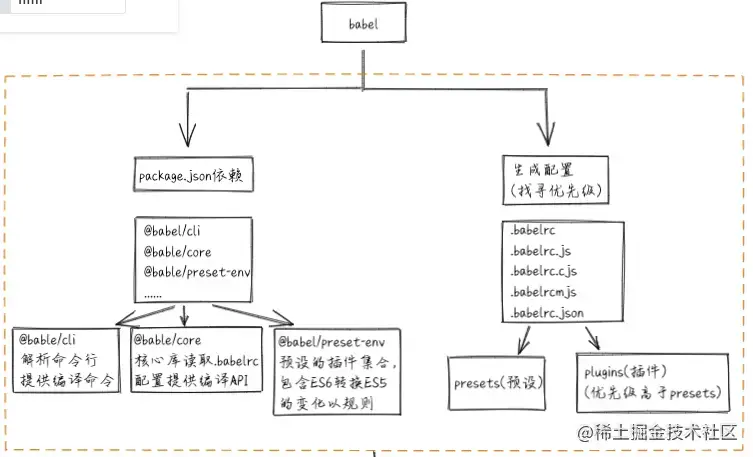
# 简单描述一下 Babel 的编译过程特别重要
概念
Babel 是一个 JavaScript 编译器,是一个工具链,主要用于将采用 ECMAScript 2015+ 语法编写的代码转换为向后兼容的 JavaScript 语法,以便能够运行在当前和旧版本的浏览器或其他环境中。
Babel 本质上就是在操作 AST 来完成代码的转译。AST是抽象语法树(Abstract Syntax Tree, AST)
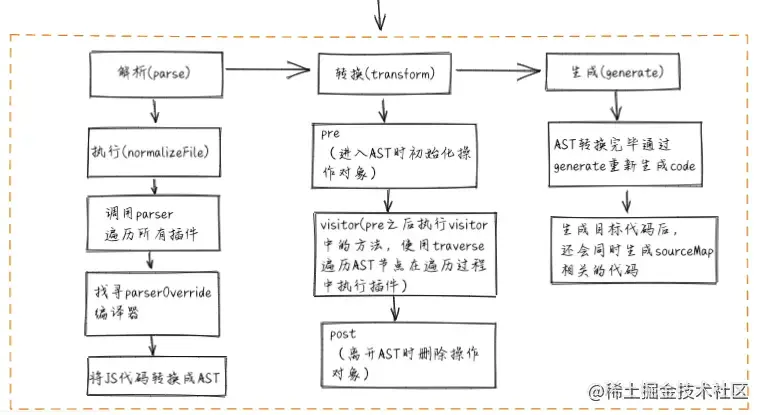
Babel 的功能很纯粹,它只是一个编译器。大多数编译器的工作过程可以分为三部分:
- 解析(
Parse) :将源代码转换成更加抽象的表示方法(例如抽象语法树)。包括词法分析和语法分析。词法分析主要把字符流源代码(Char Stream)转换成令牌流(Token Stream),语法分析主要是将令牌流转换成抽象语法树(Abstract Syntax Tree,AST)。 - 转换(
Transform) :通过Babel的插件能力,对(抽象语法树)做一些特殊处理,将高版本语法的AST转换成支持低版本语法的AST。让它符合编译器的期望,当然在此过程中也可以对AST的Node节点进行优化操作,比如添加、更新以及移除节点等。 - 生成(
Generate) :将AST转换成字符串形式的低版本代码,同时也能创建Source Map映射。
经过这三个阶段,代码就被 Babel 转译成功了。
# 列举一下有哪些捕获/监控错误的方式特别重要
try/catch
能捕获常规运行时错误,语法错误和异步错误不行
// 常规运行时错误,可以捕获 ✅
try {
console.log(notdefined);
} catch(e) {
console.log('捕获到异常:', e);
}
// 语法错误,不能捕获 ❌
try {
const notdefined,
} catch(e) {
console.log('捕获到异常:', e);
}
// 异步错误,不能捕获 ❌
try {
setTimeout(() => {
console.log(notdefined);
}, 0)
} catch(e) {
console.log('捕获到异常:',e);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
window.onerror
pure js错误收集,window.onerror,当JS运行时错误发生时,window会触发一个ErrorEvent接口的error事件。
/**
* @param {String} message 错误信息
* @param {String} source 出错文件
* @param {Number} lineno 行号
* @param {Number} colno 列号
* @param {Object} error Error对象
*/
window.onerror = function(message, source, lineno, colno, error) {
console.log('捕获到异常:', {message, source, lineno, colno, error});
}
2
3
4
5
6
7
8
9
10
11
先验证下几个错误是否可以捕获。
// 常规运行时错误,可以捕获 ✅
window.onerror = function(message, source, lineno, colno, error) {
console.log('捕获到异常:',{message, source, lineno, colno, error});
}
console.log(notdefined);
// 语法错误,不能捕获 ❌
window.onerror = function(message, source, lineno, colno, error) {
console.log('捕获到异常:',{message, source, lineno, colno, error});
}
const notdefined,
// 异步错误,可以捕获 ✅
window.onerror = function(message, source, lineno, colno, error) {
console.log('捕获到异常:',{message, source, lineno, colno, error});
}
setTimeout(() => {
console.log(notdefined);
}, 0)
// 资源错误,不能捕获 ❌
<script>
window.onerror = function(message, source, lineno, colno, error) {
console.log('捕获到异常:',{message, source, lineno, colno, error});
return true;
}
</script>
<img src="https://yun.tuia.cn/image/kkk.png">
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
window.addEventListener
当一项资源(如图片或脚本)加载失败,加载资源的元素会触发一个
Event接口的error事件,这些error事件不会向上冒泡到window,但能被捕获。而window.onerror不能监测捕获。
// 图片、script、css加载错误,都能被捕获 ✅
<script>
window.addEventListener('error', (error) => {
console.log('捕获到异常:', error);
}, true)
</script>
<img src="https://yun.tuia.cn/image/kkk.png">
<script src="https://yun.tuia.cn/foundnull.js"></script>
<link href="https://yun.tuia.cn/foundnull.css" rel="stylesheet"/>
// new Image错误,不能捕获 ❌
<script>
window.addEventListener('error', (error) => {
console.log('捕获到异常:', error);
}, true)
</script>
<script>
new Image().src = 'https://yun.tuia.cn/image/lll.png'
</script>
// fetch错误,不能捕获 ❌
<script>
window.addEventListener('error', (error) => {
console.log('捕获到异常:', error);
}, true)
</script>
<script>
fetch('https://tuia.cn/test')
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
new Image运用的比较少,可以单独自己处理自己的错误。
但通用的fetch怎么办呢,fetch返回Promise,但Promise的错误不能被捕获,怎么办呢?
Promise错误
- 普通
Promise错误
try/catch不能捕获Promise中的错误
// try/catch 不能处理 JSON.parse 的错误,因为它在 Promise 中
try {
new Promise((resolve,reject) => {
JSON.parse('')
resolve();
})
} catch(err) {
console.error('in try catch', err)
}
// 需要使用catch方法
new Promise((resolve,reject) => {
JSON.parse('')
resolve();
}).catch(err => {
console.log('in catch fn', err)
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
async错误
try/catch不能捕获async包裹的错误
const getJSON = async () => {
throw new Error('inner error')
}
// 通过try/catch处理
const makeRequest = async () => {
try {
// 捕获不到
JSON.parse(getJSON());
} catch (err) {
console.log('outer', err);
}
};
try {
// try/catch不到
makeRequest()
} catch(err) {
console.error('in try catch', err)
}
try {
// 需要await,才能捕获到
await makeRequest()
} catch(err) {
console.error('in try catch', err)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import chunk错误
import其实返回的也是一个promise,因此使用如下两种方式捕获错误
// Promise catch方法
import(/* webpackChunkName: "incentive" */'./index').then(module => {
module.default()
}).catch((err) => {
console.error('in catch fn', err)
})
// await 方法,try catch
try {
const module = await import(/* webpackChunkName: "incentive" */'./index');
module.default()
} catch(err) {
console.error('in try catch', err)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
以上三种其实归结为Promise类型错误,可以通过unhandledrejection捕获
// 全局统一处理Promise
window.addEventListener("unhandledrejection", function(e){
console.log('捕获到异常:', e);
});
fetch('https://tuia.cn/test')
2
3
4
5
不过捕捉不到行数,触发时间在被
reject但没有reject处理的时候,可能发生在window下,也可能在Worker中
Vue错误
由于
Vue会捕获所有Vue单文件组件或者Vue.extend继承的代码,所以在Vue里面出现的错误,并不会直接被window.onerror捕获,而是会抛给Vue.config.errorHandler。
/**
* 全局捕获Vue错误,直接扔出给onerror处理
*/
Vue.config.errorHandler = function (err) {
setTimeout(() => {
throw err
})
}
2
3
4
5
6
7
8
React错误
react通过componentDidCatch,声明一个错误边界的组件
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
static getDerivedStateFromError(error) {
// 更新 state 使下一次渲染能够显示降级后的 UI
return { hasError: true };
}
componentDidCatch(error, errorInfo) {
// 你同样可以将错误日志上报给服务器
logErrorToMyService(error, errorInfo);
}
render() {
if (this.state.hasError) {
// 你可以自定义降级后的 UI 并渲染
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}
class App extends React.Component {
render() {
return (
<ErrorBoundary>
<MyWidget />
</ErrorBoundary>
)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
但error boundaries并不会捕捉以下错误:React事件处理,异步代码,error boundaries自己抛出的错误
# 如何判断当前页面是白屏
在页面中取多个采样点,使用elementFromPoint方法获取采样点的元素,判断采样点的元素是否为有效元素
关于采样点的定义,以页面为中心的 水平 和 垂直线上,来定义多个采样点。
在高度为一半的时候位置下横坐标均分取九个点,宽度为一半的时候纵坐标取九个点
// modules/xhr.ts
export default function checkWhiteScreen() {
// 最顶层的空白元素(判断是白屏的依据)
const wrapperElements = ["html", "body", "#root"];
let emptyPoints = 0; // 记录空白的点的个数
function getSelector(element: Element) {
let selector;
if (element.id) {
selector = `#${element.id}`;
} else if (element.className && typeof element.className === "string") {
// prettier-ignore
selector = "." + element.className.split(" ").filter(item => !!item).join(".");
} else {
selector = element.nodeName.toLowerCase();
}
return selector;
}
function isWrapper(element: Element) {
const selector = getSelector(element);
if (wrapperElements.indexOf(selector) > -1) {
emptyPoints++; // 是空白点
}
}
for (let i = 1; i <= 9; i++) {
// 在高度一半的位置,横坐标均分取 9 个点,查看这 9 个点上的元素
const xElements = document.elementFromPoint(
(window.innerWidth / 10) * i,
window.innerHeight / 2,
);
// 在宽度一半的位置,纵坐标均分取 9 个点,查看这 9 个点上的元素
const yElements = document.elementFromPoint(
window.innerWidth / 2,
(window.innerHeight / 10) * i,
);
// 判断点的位置,是否是空白元素
isWrapper(xElements!);
isWrapper(yElements!);
}
// 定义阈值,比如 当所有的点(18个)都是空白点,那么就认为是空白页面,有一个点上有元素,就认为不是空白页面。
if (emptyPoints === 18) {
return true;
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 统计页面指标
统计页面加载时间
fetchStart:浏览器开始发起 HTTP 请求文档的时间; domContentLoadedEventStart:DOM 树构建完成后触发 DOMContentLoaded 事件的时间; loadEventStart:页面所有资源(包括图片)加载完成后触发 window.onload 事件发生的时间。
const { fetchStart, domContentLoadedEventStart, loadEventStart } = navigationEntry as PerformanceNavigationTiming;
// DOM 树构建完成后触发 DOMContentLoaded 事件
DOMContentLoadedTime = domContentLoadedEventStart - fetchStart;
// 页面完整的加载时间
loadTime = loadEventStart - fetchStart;
2
3
4
5
6
7
FP(First Paint(首次绘制 - 首次像素绘制)) FCP(First Content Paint(首次内容绘制))
FP 和 FCP 指标都可以通过 PerformanceObserver API 观察 type: paint 来计算。
// modules/paint.ts
export default function injectPaint() {
if (PerformanceObserver) {
let FP, FCP;
// 1、监控性能指标 FP(First Paint) 和 FCP(First Contentful Paint)
const observerFPAndFCP = new PerformanceObserver(function (entryList) {
const perfEntries = entryList.getEntries();
for (const perfEntry of perfEntries) {
if (perfEntry.name === "first-paint") {
FP = perfEntry;
console.log("首次像素绘制 时间:", FP?.startTime);
} else if (perfEntry.name === "first-contentful-paint") {
FCP = perfEntry;
console.log("首次内容绘制 时间:", FCP?.startTime);
observerFPAndFCP.disconnect(); // 得到 FCP 后,断开观察,不再观察了
}
}
});
// 观察 paint 相关性能指标
observerFPAndFCP.observe({ entryTypes: ["paint"] });
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
FMP(First Meaningful Paint(首次有意义内容绘制))
LCP, (Largest Contentful Paint)(最大内容渲染)
// modules/paint.ts
export default function injectPaint() {
if (PerformanceObserver) {
let FP, FCP, FMP;
...
// 2、监控性能指标:FMP(First Meaningful Paint)
const observerFMP = new PerformanceObserver(entryList => {
const perfEntries = entryList.getEntries();
FMP = perfEntries[0];
console.log("首次有意义元素绘制 时间:", FMP?.startTime);
observerFMP.disconnect(); // 断开观察,不再观察了
});
observerFMP.observe({ entryTypes: ["element"] });
}
}
// modules/paint.ts
export default function injectPaint() {
if (PerformanceObserver) {
let FP, FCP, FMP, LCP;
...
// 3、创建性能观察者,观察 LCP
const observerLCP = new PerformanceObserver(entryList => {
const perfEntries = entryList.getEntries();
LCP = perfEntries[0];
console.log("最大内容绘制 时间:", LCP?.startTime, perfEntries);
});
// 观察页面中最大内容的绘制
observerLCP.observe({ entryTypes: ["largest-contentful-paint"] });
// TODO... 在上报性能指标数据的时候,停止观察。
observerLCP.disconnect();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
统计LongTask
// module/longTask.ts
import { PerformanceLog } from "../interface";
import getLastEvent from "../utils/getLastEvent";
import getSelector from "../utils/getSelector";
import tracker from "../utils/tracker";
export default function injectLongTask() {
if (PerformanceObserver) {
const observerLongTask = new PerformanceObserver(list => {
list.getEntries().forEach(entry => {
// 执行时长大于 100 ms
if (entry.duration > 100) {
const lastEvent = getLastEvent();
const log: LongTaskLog = {
type: "longTask",
startTime: entry.startTime, // 开始时间
duration: entry.duration, // 持续时间
selector: lastEvent ? getSelector() : "",
eventType: lastEvent?.type,
};
tracker.send(log);
}
});
});
observerLongTask.observe({ entryTypes: ["longtask"] });
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
FP / FCP / FMP / LCP 优化
减少关键资源大小和数量
- 压缩资源(HTML/CSS/JS)图片用webp
- 代码切割,路由级别懒加载,Tree Shaking
优化关键渲染路径
- 非必要的JS使用defer/async
- 减少渲染阻塞资源:使用 Preload / Prefetch 加速资源准备
服务端优化
- 开启ssr ssg
- 使用CDN
LCP专门优化:LCP元素不要被懒加载,字体延迟加载
longtask优化
- 使用 requestAnimationFrame/requestIdelCallback(把大任务切片分批执行,避免长时间占用主线程)
- 使用web worker
- 避免巨大的匿名函数和闭包链
- 懒加载,延迟或异步加载广告
# 前端容灾是什么 该怎么解决
前端容灾指的因为各种原因后端接口挂了(比如服务器断电断网等等),前端依然能保证页面信息能完整展示。
比如 banner 或者列表之类的等等数据是从接口获取的,要是接口获取不到了,怎么办呢?
LocalStorage
在接口正常返回的时候把数据都存到 LocalStorage ,可以把接口路径作为 key,返回的数据作为 value
然后之次再请求,只要请求失败,就读取 LocalStorage,把上次的数据拿出来展示,并上报错误信息,以获得缓冲时间
CDN
同时,每次更新都要备份一份静态数据放到CDN
在接口请求失败的时候,并且 LocalStorage 也没有数据的情况下,就去 CDN 摘取备份的静态数据
Service Worker
假如不只是接口数据,整个 html 都想存起来,就可以使用 Service Worker 做离线存储
利用 Service Worker 的请求拦截,不管是存接口数据,还是存页面静态资源文件都可以
// 拦截所有请求事件 缓存中有请求的数据就直接用缓存,否则去请求数据
self.addEventListener('fetch', e => {
// 查找request中被缓存命中的response
e.respondWith(caches.match(e.request).then( response => {
if (response) {
return response
}
console.log('fetch source')
}))
})
2
3
4
5
6
7
8
9
10
做好这些,整个网站就完全可以离线运行了,但是问题也很明显,就是时效性较高的页面可能会有数据无法同步更新的问题(比如商家库存不足了显示不一致)
另外要注意的是要保证前端页面自身可发布更新,比如页面异常后,此时业务系统要发新版本进行修复和更新,要能确保新版本的资源可以全量替换旧版本的线上资源
# 前端工程化的理解
模块化
将一个大的文件,拆分成多个相互依赖的小文件,按一个个模块来划分
组件化
页面上所有的东西都可以看成组件,页面是个大型组件,可以拆成若干个中型组件,然后中型组件还可以再拆,拆成若干个小型组件
- 组件化≠模块化。模块化只是在文件层面上,对代码和资源的拆分;组件化是在设计层面上,对于
UI的拆分 - 目前市场上的组件化的框架,主要的有
Vue,React,Angular2
规范化
在项目规划初期制定的好坏对于后期的开发有一定影响。包括的规范有
- 目录结构的制定
- 编码规范
editorconfig、eslint配置,git husky在git commit后自动通过规范化修复 - 前后端接口规范
- 文档规范
- 组件管理
Git分支管理Commit描述规范commitizen使用统一风格的commit语句- 定期
codeReview - 视觉图标规范
自动化
也就是简单重复的工作交给机器来做,自动化也就是有很多自动化工具代替我们来完成,例如持续集成、自动化构建、自动化部署、自动化测试等等
笔记
CI是什么
- 持续集成:当代码仓库代码发生变更,就会自动对代码进行测试和构建,反馈运行结果。
CD是什么
- 持续交付:持续交付是在持续集成的基础上,可以将集成后的代码依次部署到测试环境、予发布环境、生产环境等中