 浏览器缓存
浏览器缓存
# 浏览器缓存
# 介绍一下浏览器的缓存机制特别重要
全过程:
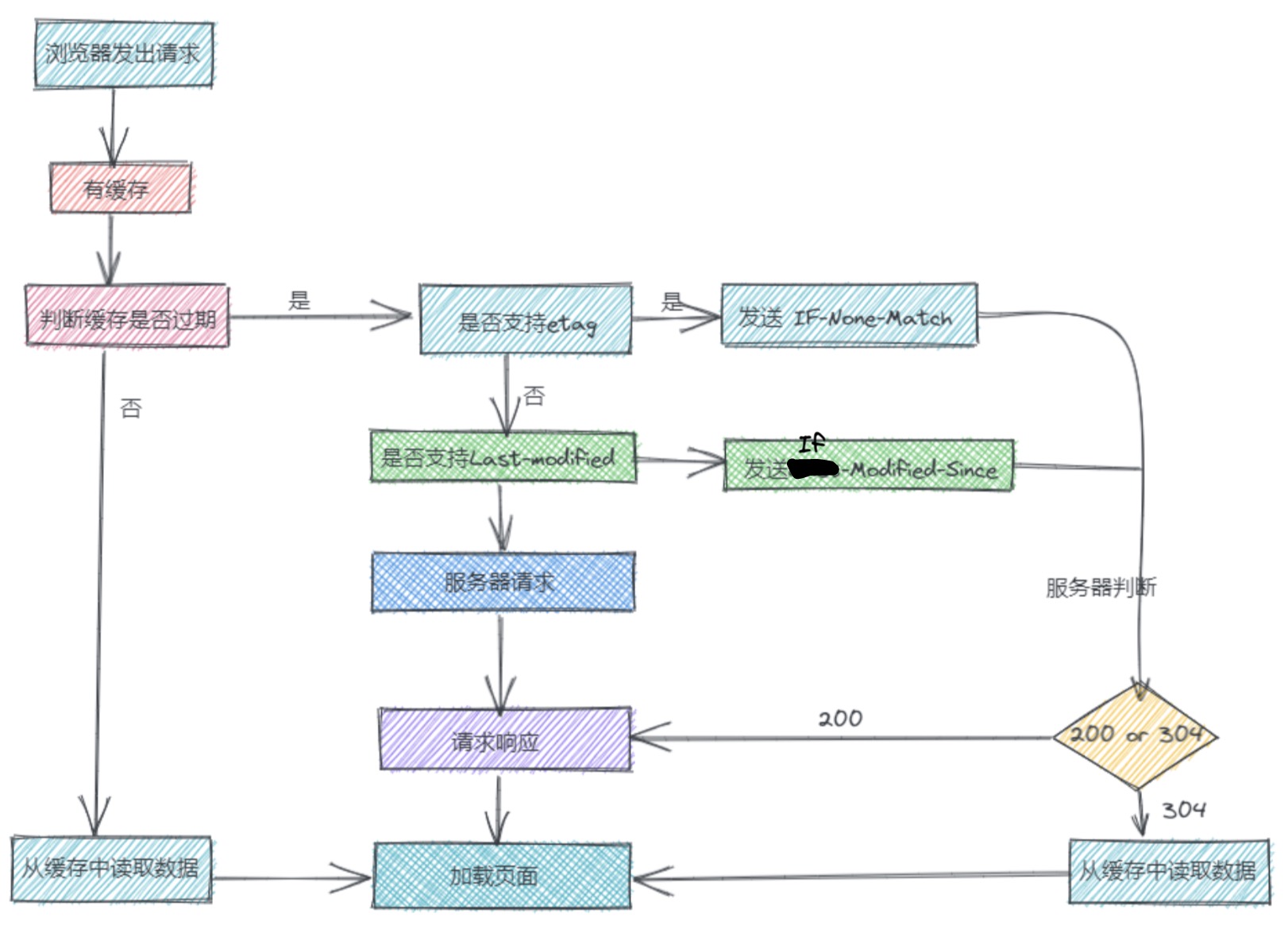
浏览器第一次加载资源,服务器返回
200,浏览器从服务器下载资源文件,并缓存资源文件与response header,以供下次加载时对比使用;下一次加载资源时,由于强制缓存优先级较高,先比较当前时间与上一次返回
200时的时间差,如果没有超过cache-control设置的max-age,则没有过期,并命中强缓存,直接从本地读取资源。如果浏览器不支持HTTP1.1,则使用expires头判断是否过期;如果资源已过期,则表明强制缓存没有被命中,则开始协商缓存,向服务器发送带有
If-None-Match和If-Modified-Since的请求;服务器收到请求后,优先根据
Etag的值判断被请求的文件有没有做修改,Etag值一致则没有修改,命中协商缓存,返回304;如果不一致则有改动,直接返回新的资源文件带上新的Etag值并返回200;如果服务器收到的请求没有
Etag值,则将If-Modified-Since和被请求文件的最后修改时间做比对,一致则命中协商缓存,返回304;不一致则返回新的last-modified和文件并返回200;
 很多网站的资源后面都加了版本号,这样做的目的是:每次升级了
很多网站的资源后面都加了版本号,这样做的目的是:每次升级了JS 或 CSS 文件后,为了防止浏览器进行缓存,强制改变版本号,客户端浏览器就会重新下载新的 JS 或 CSS 文件 ,以保证用户能够及时获得网站的最新更新。
# 浏览器资源缓存的位置有哪些
资源缓存的位置一共有 3 种,按优先级从高到低分别是:
Service Worker:Service Worker运行在JavaScript主线程之外,虽然由于脱离了浏览器窗体无法直接访问DOM,但是它可以完成离线缓存、消息推送、网络代理等功能。它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。当Service Worker没有命中缓存的时候,需要去调用fetch函数获取数据。也就是说,如果没有在Service Worker命中缓存,会根据缓存查找优先级去查找数据。但是不管是从Memory Cache中还是从网络请求中获取的数据,浏览器都会显示是从Service Worker中获取的内容。Memory Cache:Memory Cache就是内存缓存,它的效率最快,但是缓存持续性很短,会随着进程的释放而释放。一旦我们关闭Tab页面,内存即刻被释放。Disk Cache:Disk Cache也就是存储在硬盘中的缓存,读取速度慢点,但什么都能存储到磁盘中,比Memory Cache胜在容量和存储时效性上。在所有浏览器缓存中,Disk Cache覆盖面基本是最大的。它会根据HTTP Herder中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据Push Cache是HTTP/2中的内容,当以上三种缓存都没有命中时,它才会被使用。并且缓存时间也很短暂,只在会话(Session)中存在,一旦会话结束就被释放。其具有以下特点:所有的资源都能被推送,但是
Edge和Safari浏览器兼容性不怎么好可以推送
no-cache和no-store的资源一旦连接被关闭,
Push Cache就被释放多个页面可以使用相同的
HTTP/2连接,也就是说能使用同样的缓存Push Cache中的缓存只能被使用一次浏览器可以拒绝接受已经存在的资源推送
可以给其他域名推送资源
# 协商缓存和强缓存的区别特别重要
强缓存
概念
使用强缓存策略时,如果缓存资源有效,则直接使用缓存资源,不必再向服务器发起请求。
强缓存策略可以通过两种方式来设置,分别是 http 头信息中的 Expires 属性 和 Cache-Control 属性。
Expires
服务器通过在响应头中添加 Expires 属性,来指定资源的过期时间。在过期时间以内,该资源可以被缓存使用,不必再向服务器发送请求。这个时间是一个绝对时间,它是服务器的时间,因此可能存在这样的问题,就是客户端的时间和服务器端的时间不一致,或者用户可以对客户端时间进行修改的情况,这样就可能会影响缓存命中的结果
Expires 是 http1.0 中的方式,因为它的一些缺点,在 HTTP 1.1 中提出了一个新的头部属性就是 Cache-Control 属性,它提供了对资源的缓存的更精确的控制。它有很多不同的值,
Cache-Control可设置的字段:
public:设置了该字段值的资源表示可以被任何对象(包括:发送请求的客户端、代理服务器等等)缓存。这个字段值不常用,一般还是使用max-age=来精确控制;private:设置了该字段值的资源只能被用户浏览器缓存,不允许任何代理服务器缓存。在实际开发当中,对于一些含有用户信息的HTML,通常都要设置这个字段值,避免代理服务器(CDN)缓存;no-cache:设置了该字段需要先和服务端确认返回的资源是否发生了变化,如果资源未发生变化,则直接使用缓存好的资源;no-store:设置了该字段表示禁止任何缓存,每次都会向服务端发起新的请求,拉取最新的资源;max-age=:设置缓存的最大有效期,单位为秒;s-maxage=:优先级高于max-age=,仅适用于共享缓存(CDN),优先级高于max-age或者Expires头;max-stale[=]:设置了该字段表明客户端愿意接收已经过期的资源,但是不能超过给定的时间限制。
一般来说只需要设置其中一种方式就可以实现强缓存策略,当两种方式一起使用时,Cache-Control 的优先级要高于 Expires。
no-cache 和 no-store 很容易混淆:
no-cache 是指先要和服务器确认是否有资源更新,在进行判断。也就是说没有强缓存,但是会有协商缓存;
no-store 是指不使用任何缓存,每次请求都直接从服务器获取资源。
协商缓存
概念
如果命中强制缓存,我们无需发起新的请求,直接使用缓存内容,如果没有命中强制缓存,如果设置了协商缓存,这个时候协商缓存就会发挥作用了。
上面已经说到了,命中协商缓存的条件有:
expires过期cache-control的max-age=xxx过期了 或者值为no-cache
使用协商缓存策略时,会先向服务器发送一个请求,如果资源没有发生修改,则返回一个 304 状态,让浏览器使用本地的缓存副本。如果资源发生了修改,则返回修改后的资源。
协商缓存也可以通过两种方式来设置,分别是 http 头信息中的 Etag 和 Last-Modified 属性。
Last-Modified
服务器通过在响应头中添加 Last-Modified 属性来指出资源最后一次修改的时间,当浏览器下一次发起请求时,会在请求头中添加一个 If-Modified-Since 的属性,属性值为上一次资源返回时的 Last-Modified 的值。当请求发送到服务器后服务器会通过这个属性来和资源的最后一次的修改时间来进行比较,以此来判断资源是否做了修改。如果资源没有修改,那么返回 304 状态,让客户端使用本地的缓存。如果资源已经被修改了,则返回修改后的资源。
这种方法有一个缺点
就是 Last-Modified 标注的最后修改时间只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,那么文件已将改变了但是 Last-Modified 却没有改变,这样会造成缓存命中的不准确。
Etag
服务器在返回资源的时候,在头信息中添加了 Etag 属性,这个属性是资源生成的唯一标识符,当资源发生改变的时候,这个值也会发生改变。在下一次资源请求时,浏览器会在请求头中添加一个 If-None-Match 属性,这个属性的值就是上次返回的资源的 Etag 的值。服务接收到请求后会根据这个值来和资源当前的 Etag 的值来进行比较,以此来判断资源是否发生改变,是否需要返回资源。通过这种方式,比 Last-Modified 的方式更加精确。
这种方法也有缺点
- 计算成本。生成哈希值相对于读取文件修改时间而言是一个开销比较大的操作,尤其是对于大文件而言。如果要精确计算则需读取完整的文件内容,如果从性能方面考虑,只读取文件部分内容,又容易判断出错。
- 计算误差。
HTTP并没有规定哈希值的计算方法,所以不同服务端可能会采用不同的哈希值计算方式。这样带来的问题是,同一个资源,在两台服务端产生的Etag可能是不相同的,所以对于使用服务器集群来处理请求的网站来说,使用Etag的缓存命中率会有所降低。
优先级
当 Last-Modified 和 Etag 属性同时出现的时候,Etag 的优先级更高。使用协商缓存的时候,服务器需要考虑负载平衡的问题,因此多个服务器上资源的 Last-Modified 应该保持一致,因为每个服务器上 Etag 的值都不一样,因此在考虑负载平衡时,最好不要设置 Etag 属性。
总结
强缓存策略 和 协商缓存策略 在缓存命中时都会直接使用本地的缓存副本,区别只在于协商缓存会向服务器发送一次请求。它们缓存不命中时,都会向服务器发送请求来获取资源。在实际的缓存机制中,强缓存策略和协商缓存策略是一起合作使用的。浏览器首先会根据请求的信息判断,强缓存是否命中,如果命中则直接使用资源。
如果不命中则根据头信息向服务器发起请求,使用协商缓存,如果协商缓存命中的话,则服务器不返回资源,浏览器直接使用本地资源的副本,如果协商缓存不命中,则浏览器返回最新的资源给浏览器。
# 为什么需要浏览器缓存
对于浏览器的缓存,主要针对的是前端的静态资源,最好的效果就是,在发起请求之后,拉取相应的静态资源,并保存在本地。
如果服务器的静态资源没有更新,那么在下次请求的时候,就直接从本地读取即可,如果服务器的静态资源已经更新,那么我们再次请求的时候,就到服务器拉取新的资源,并保存在本地。这样就大大的减少了请求的次数,提高了网站的性能。这就要用到浏览器的缓存策略了。
浏览器缓存指的是浏览器将用户请求过的静态资源,存储到电脑本地磁盘中,当浏览器再次访问时,就可以直接从本地加载,不需要再去服务端请求了。
使用浏览器缓存,有以下优点:
- 减少了服务器的负担,提高了网站的性能
- 加快了客户端网页的加载速度
- 减少了多余网络数据传输
# 知道启发式缓存吗?加分
如果响应中未显示Expires,Cache-Control:max-age或Cache-Control:s-maxage,并且响应中不包含其他有关缓存的限制,缓存可以使用启发式方法计算新鲜度寿命。通常会根据响应头中的2个时间字段 Date 减去 Last-Modified 值的 10% 作为缓存时间。
// Date 减去 Last-Modified 值的 10% 作为缓存时间。
// Date:创建报文的日期时间, Last-Modified 服务器声明文档最后被修改时间
response_is_fresh = max(0,(Date - Last-Modified)) % 10
2
3
# HTTP的代理缓存亮点
为什么产生代理缓存?
对于源服务器来说,它也是有缓存的,比如 Redis,Memcache ,但对于 HTTP 缓存来说,如果每次客户端缓存失效都要到源服务器获取,那给源服务器的压力是很大的。
由此引入了缓存代理的机制。让代理服务器接管一部分的服务端HTTP缓存,客户端缓存过期后就近到代理缓存中获取,代理缓存过期了才请求源服务器,这样流量巨大的时候能明显降低源服务器的压力。
那缓存代理究竟是如何做到的呢?
总的来说,缓存代理的控制分为两部分,一部分是源服务器端的控制,一部分是客户端的控制。
源服务器的缓存控制
private 和 public
在源服务器的响应头中,会加上Cache-Control这个字段进行缓存控制字段,那么它的值当中可以加入private或者public表示是否允许代理服务器缓存,前者禁止,后者为允许。
比如对于一些非常私密的数据,如果缓存到代理服务器,别人直接访问代理就可以拿到这些数据,是非常危险的,因此对于这些数据一般是不会允许代理服务器进行缓存的,将响应头部的Cache-Control设为private,而不是public。
proxy-revalidate
must-revalidate的意思是客户端缓存过期就去源服务器获取,而proxy-revalidate则表示代理服务器的缓存过期后到源服务器获取。
s-maxage
s是share的意思,限定了缓存在代理服务器中可以存放多久,和限制客户端缓存时间的max-age并不冲突。
讲了这几个字段,我们不妨来举个小🌰,源服务器在响应头中加入这样一个字段:
Cache-Control: public, max-age=1000, s-maxage=2000
相当于源服务器说: 我这个响应是允许代理服务器缓存的,客户端缓存过期了到代理中拿,并且在客户端的缓存时间为 1000 秒,在代理服务器中的缓存时间为 2000 s。
客户端的缓存控制
max-stale 和 min-fresh
在客户端的请求头中,可以加入这两个字段,来对代理服务器上的缓存进行宽容和限制操作。比如:
max-stale: 5
表示客户端到代理服务器上拿缓存的时候,即使代理缓存过期了也不要紧,只要过期时间在 5秒之内,还是可以从代理中获取的。
又比如:
min-fresh: 5
表示代理缓存需要一定的新鲜度,不要等到缓存刚好到期再拿,一定要在到期前 5 秒之前的时间拿,否则拿不到。
only-if-cached
这个字段加上后表示客户端只会接受代理缓存,而不会接受源服务器的响应。如果代理缓存无效,则直接返回504(Gateway Timeout)。
# 点击刷新按钮或者按 F5、按 Ctrl+F5 (强制刷新)、地址栏回车有什么区别?重要
点击刷新按钮或者按
F5: 浏览器直接对本地的缓存文件过期,但是会带上If-Modifed-Since,If-None-Match,这就意味着服务器会对文件检查新鲜度,返回结果可能是304,也有可能是200。用户按
Ctrl+F5(强制刷新): 浏览器不仅会对本地文件过期,而且不会带上If-Modifed-Since,If-None-Match,相当于之前从来没有请求过,返回结果是200。地址栏回车: 浏览器发起请求,按照正常流程,本地检查是否过期,然后服务器检查新鲜度,最后返回内容。